
Python网络爬取与robots.txt协议
0. 背景
现在很多Python入门的教程、书籍,都是以网络爬虫程序为例;其普及之广直追大学里人人都写过的『图书馆管理系统』了。但是这些教程一般都只强调Python程序的简单、第三方库的强大,但很少有教程认真讲讲robots.txt协议(顺便提一句的都很少)。
爬取网络信息而不遵守甚至不知道robots.txt协议 —— 说轻了,是闹个左刀右叉的礼仪笑话;说重了,有可能在不知不觉间就吃了官司呢1。
那我们今天就来讲讲什么是robots.txt协议,以及在Python中怎么使用robots.txt。
1. robots.txt协议简介
robots.txt协议的官方名称为Robots Exclusion Protocol(中译:网络爬虫排除标准)。此协议可以让网站告诉各方爬虫程序:该网站的哪些页面可以抓取,哪些页面不能抓取。
首先需要说明的是,这个robots.txt协议并不是ISO、W3C这种行业垄断组织协商一致、强制推行的协议或标准。robots.txt协议是由荷兰软件工程师Martijn Koster(网络搜索引擎先驱之一)在1994年提出来的。提出之后,该协议很快就成为业界的事实标准;绝大多数搜索引擎,如Ask、AOL、Baidu、Bing、DuckDuckGo、Google、Yahoo!、Yandex等,都遵从这个事实协议。
robots.txt协议基本内容如下:
- 如果某网站想要阻止爬虫程序爬取其某些网页,则可以在该网站的根目录下放置一个名为robots.txt(文件名全部为小写字母)的ASCII纯文本说明文件(写法及含义见后续说明);
- 如果该网站没有放置robots.txt文件,则该网站对爬虫程序没有任何限制;
- robots.txt文件是大小写敏感的;
- robots.txt文件仅仅是一个指示性文件,并没有绝对的强制效力,爬虫程序可以忽略该文件;因此,敏感数据不能依靠robots.txt来保护。
2. robots.txt的写法及含义
官方网站(www.robotstxt.org)的说明自然最为权威。
我们这里简单总结一下:
标准robots.txt文件中,只有三种语句:
注释语句。形如:
# bala balaUser-agent语句。形如:
User-agent: agent-name,指明其后Disallow语句所针对的爬虫程序的名字。常见的爬虫程序有:google机器人:Googlebot、百度蜘蛛:Baiduspider、yahoo爬虫:Yahoo!slurp、alexa爬虫:ia_archiver等。通配符(*)指代所有爬虫程序。Disallow语句。形如:
Disallow: /path-name/,指明不希望哪个目录下的内容(或匹配的内容)被爬虫程序访问。
在robots.txt文件中,User-agent和Disallow语句组成一个或多个如下的段落:
User-agent: agent-name
Disallow: /path1/
Disallow: /path2/
从语句含义可知,每段针对一种爬虫程序,告诉该爬虫程序不要爬取本站的哪些内容。
User-agent: *段最多只应出现一次,且应是文件的最后一段。我们自己编写的爬虫程序,通常应受User-agent: *段约束。
2.1 一些例子
- 允许所有的爬虫程序访问整个网站:
User-agent: *
Disallow:
- 禁止所有的爬虫程序访问:
User-agent: *
Disallow: /
- 禁止某个爬虫程序(BadBot)访问特定目录,但允许其他爬虫程序访问整个网站:
User-agent: BadBot
Disallow: /private/User-agent: *
Disallow:
- 2017年12月16日百度百科的robots.txt文件(部分),允许一些特定的爬虫程序访问某些内容,但禁止其他爬虫程序访问
…
User-agent: EasouSpider
Disallow: /update
Disallow: /history
Disallow: /usercard
Disallow: /usercenter
Disallow: /client/
Disallow: /divideload/
Disallow: /edit/
Disallow: /l/User-agent: *
Disallow: /
- 2017年12月16日澳大利亚政府(www.australia.gov.au)的robots.xt文件(部分)
# This file is to prevent the crawling and indexing of certain parts
# of your site by web crawlers and spiders run by sites like Yahoo!
# and Google. By telling these “robots” where not to go on your site,
# you save bandwidth and server resources.User-agent: *
Crawl-delay: 10
# Directories
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /profiles/
Disallow: /content/
# Files
Disallow: /CHANGELOG.txt
# Paths (clean URLs)
Disallow: /admin/
# Paths (no clean URLs)
Disallow: /?q=search/
由于robots.txt并非业界强制性标准,因此还有一些非标准扩展,如Crawl-delay(两次爬取之间需等待的秒数)、sitemap(网站地图,指导爬虫程序爬取)等等,大家可以自行google。这里就不多说了。
3. Python如何处理robots.txt文件
Python标准库urllib就有处理robots.txt的模块:urllib.robotparser
使用urllib.robotparser很简单,常用步骤/语句如下:
import
1import urllib.robotparser创建一个robots.txt文件的解析器(parser)
1rp = urllib.robotparser.RobotFileParser()告诉解析器,你要检查哪个网站的robots.txt协议
1rp.set_url("http://www.australia.gov.au/robots.txt")让解析器读取该robots.txt协议
1rp.read()询问解析器,某网页按照robots.txt协议是否可以爬取
12rp.can_fetch("*", "http://www.australia.gov.au/information-and-services/benefits-and-payments")rp.can_fetch("*", "http://www.australia.gov.au/content/index.html")robotparser还支持Crawl-delay
1rp.crawl_delay("")打印robots.txt协议内容
1print(rp)
上述若干语句的运行结果:
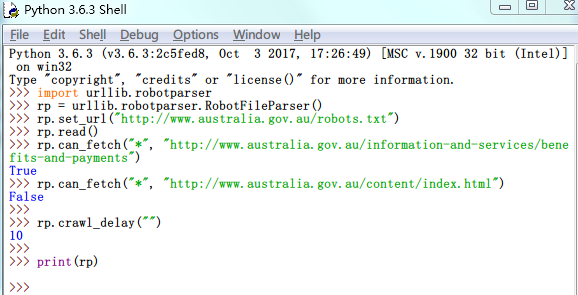
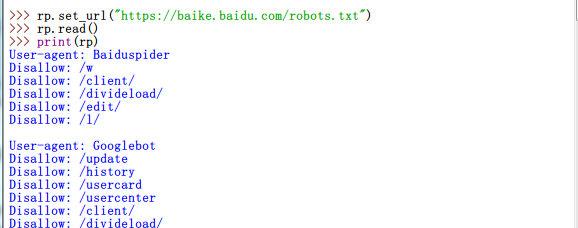
咦,别的语句工作得都非常正常,怎么print(rp)啥都没打印出来呀?说实话,我也不知道怎么回事。似乎这个版本(3.6.3)的robotparser无法打印出User-agent: *节。但好在这不影响rp.can_fetch()的使用。另外,其他指定User-agent节可以被正常print()。以百度百科为例:
Python中处理robots.txt就是这么简单!希望大家以后在爬取网站的时候,注意遵守robots.txt协议,做个文明人~~~
相关网站
英文维基 - Robots exclusion standard
尾注
- 著名的robots.txt协议相关官司包括: